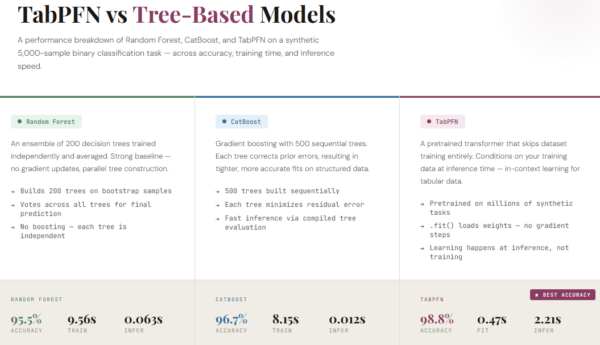
How TabPFN Leverages In-Context Learning to Achieve Superior Accuracy on Tabular Datasets Compared to Random Forest and CatBoost
Tabular data—structured information stored in rows and columns—is at the heart of most real-world machine learning problems, from healthcare records to financial transactions. Over the years, models based on decision trees, such as Random Forest, XGBoost, and CatBoost, have become the default choice

